I've been working with Docbook V5.0 a bit and started working on some processing tools to support my workflow. One of the big things is that the official Docbook Schema is Relax NG and Schematron.
Relax NG
In .net, you can create a validating XML Reader by passing in XmlReaderSettings into XmlReader.Create, but the built-in ValidationType is limited to W3C XML Schema (.xsd) or Document type definitions (.dtd). Docbook has Schema files for both, but neither are the official standard because of a slight lack of features in those schema languages.
Thankfully, the Mono team has made a Relax NG library and created a NuGet Package that is useable in Microsoft's .net. The Package ID is RelaxNG:
PM> Install-Package RelaxNG
I've created a simple Docbook XML File for testing purposes and I'm using the docbookxi.rng schema file (since I'm using XIncludes).
// using System.Xml;
// using System.Xml.Linq;
// using Commons.Xml.Relaxng;
using (XmlReader instance = new XmlTextReader("DocbookTest.xml"))
using (XmlReader grammar = new XmlTextReader("docbookxi.rng"))
using (var reader = new RelaxngValidatingReader(instance, grammar))
{
XDocument doc = XDocument.Load(reader);
Console.WriteLine("Document is using Docbook Version " +
doc.Root.Attribute("version").Value);
}
There are two ways of handling Validation Errors (in the test case, I've duplicated the <title>First Part of Book 1</title> node, which is illegal in Docbook since title can only occur once in that scenario).
If no handler is set up, this throws a Commons.Xml.Relaxng.RelaxngException with an error like Invalid start tag closing found. LocalName = title, NS = http://docbook.org/ns/docbook.file:///H:/RelaxNgValidator/bin/Debug/DocbookTest.xml line 35, column 14.
The better way is to hook up to the InvalidNodeFound Event which has a signature of bool InvalidNodeFound(XmlReader source, string message):
reader.InvalidNodeFound += (source, message) =>
{
Console.WriteLine("Error: " + message);
return true;
};
source is the RelaxngValidatingReader as an XmlReader and allows you to look at the current state to do further analysis/error recovery. message is a human readable message like "Invalid start tag found. LocalName = title, NS = http://docbook.org/ns/docbook.". The return value decides whether of not processing continues. If true, it will skip over the error - in the end, I'm going to have a proper XDocument but of course all guarantees for validity are off. If false, this will throw same RelaxngException as if there's no event handler wired up.
Generally, I prefer to make use of a lambda closure to log all errors during Validation and set a bool on failure that prevents further processing afterwards.
Schematron
Now, Relax NG is only one of the two parts of Docbook Validation, although arguably the bigger one. Schematron is employed for further validation, for example that book must have a version attribute if (and only if) it's the root element, or that otherterm on a glosssee must point to a valid glossentry. The Docbook Schematron file is in the sch directory and for this test, I've removed the <glossentry xml:id="sgml"> node from the DocbookTest.xml file. This still passes Relax NG, but is no longer a valid Docbook document.
There isn't much in terms of Schematron support in .net, but I've found a rather ancient library called Schematron.NET of which I downloaded Version 0.6 from 2004-11-02. This is messy, because I have to use the Docbook W3C XML Schema file which has embedded Schematron rules - basically docbook.xsd, xml.xsd and xlink.xsd from the /xsd directory. Thanks to this article on MSDN for pointing me to the library and to the fact that Schematron rules can be embedded into .xsd using the appinfo element.
I also need to make sure to use the XmlTextReader and not any other XmlReader - Liskov be damned!
using (XmlReader instance = new XmlTextReader("DocbookTest.xml"))
{
var schemas = new XmlSchemaCollection();
schemas.Add("http://www.w3.org/XML/1998/namespace", "xml.xsd");
schemas.Add("http://www.w3.org/1999/xlink", "xlink.xsd");
schemas.Add("http://docbook.org/ns/docbook", "docbook.xsd");
var schematron = new Validator();
schematron.AddSchemas(schemas);
schematron.Validate(instance);
}
This throws a NMatrix.Schematron.ValidationException with the message
Results from XML Schema validation:
Error: Reference to undeclared ID is 'sgml'.
At: (Line: 85, Column: 35)
There doesn't seem to be an Event Handler, but the code is very 2004-ish, with properties being set after processing. Overall, the whole approach is very messy, I'm even validating the whole document again against XSD after it's been passed through Relax NG already.
The library is also expecting the old Schematron 1.5 namespace of http://www.ascc.net/xml/schematron - which is fine for Docbook 5.0 but will be a problem once Docbook 5.1 comes out since it uses the ISO Schematron namespace of http://purl.oclc.org/dsdl/schematron.
For 5.0 it does give proper Schematron validation which is good enough for now, but overall, this isn't really a great way to do Schematron validation. Not sure if there's a better solution because I'd love to avoid starting my own .net 4.5 Schematron Validator Project 🙂
April 19th, 2014 in
Development
Important Update: In late 2014, Lenovo stared shipping their systems with adware that poses significant security threats to the users. I therefore recommend not buying any Lenovo products. The review will stay up for historical purposes, but my next Laptop won't be a Lenovo.
It's been a while since I bought a new Laptop. The last one I blogged about was an ASUS eeePC 1000HE, which is still in use as my sole Windows XP machine for interfacing with my Commodore 64 and to test games on an old Atom and GMA 950 graphics. In 2010, I bought a 13" MacBook Pro with a 2.4 GHz Core 2 Duo which served me well until late 2013 when I wanted something with a higher screen resolution (1280x800 just wasn't that great for some things) and a more power without sacrificing on battery life, Windows 7 compatibility or the ability to actually do work.
I ended up with a Lenovo ThinkPad E440.

Specs and Delivery
I ordered my E440 on February 24 as a BTO (Build-to-order) for a bit less than $700 including Tax and Shipping. For that money, I got
- Intel Core i5-4200M CPU (2.5 GHz Dual Core with Hyperthreading)
- 14.0" 1600x900 AntiGlare Screen (16:9 Aspect Ratio)
- Bigger Battery (62WH compared to the stock 48WH)
- Intel 7260AC Dual Band (2.4/5 GHz) 802.11 ac/a/b/g/n Wireless
- Windows 7 Professional 64-Bit
- Intel HD 4600 Graphics
- 4 GB RAM
- 500 GB 7200 rpm hard drive and a DVD-R drive
The laptop was delivered on April 1 - that's 36 days between ordering and delivering. This is rather ridiculous for a business laptop. Lenovo explained they had an unexpected surge of orders that clogged up their manufacturing capacity, but still, that was a bit much.
The Laptop has two memory slots, one which was filled with the 4 GB Memory I ordered and one that was empty. I had a fitting 4 GB Memory still lying around (Kingston KVR16LS11/4), so I upgraded it to 8 GB RAM immediately. I also had a 256 GB Samsung 840 Pro SSD lying around which immediately replaced the 500 GB Hard Drive.
Every Laptop should use SSDs - it makes a massive difference even over 7200 rpm drives, and the lack of a moving part increases the overall resilience. It's also extremely quiet since pretty much only the CPU draws any real power. The Graphics is an Intel HD 4600 - not the most amazing gaming chip, but it runs Reaper of Souls in 1600x900 perfectly fine, so it's good enough for my mobile gaming needs.
For reference, the AmazonBasics 14" Sleeve fits perfectly, although no space for any accessories.
Anti-Theft systems and other security features
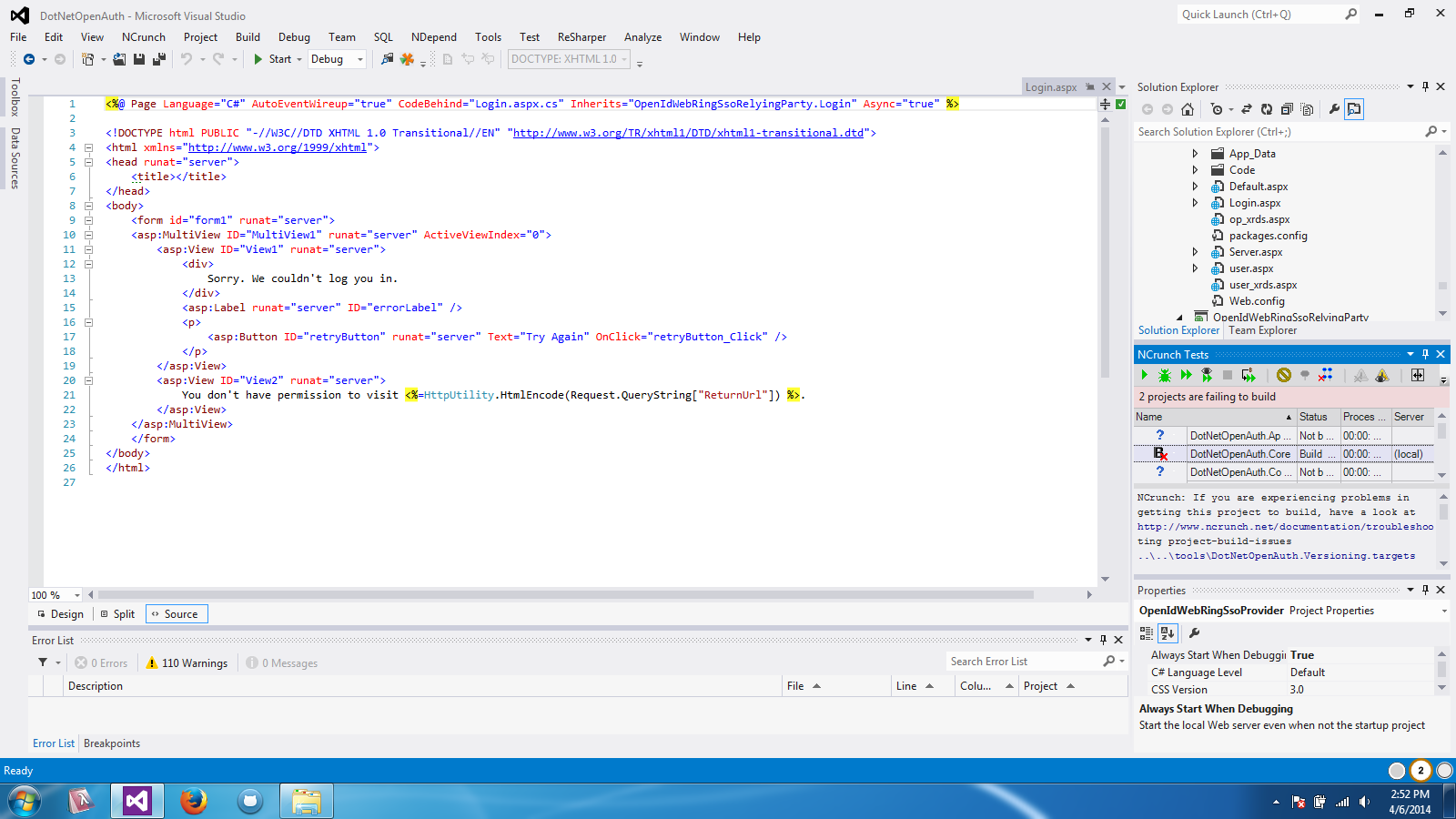
The E440 comes with Intel Anti-Theft and Computrace. Now, by virtue of being an Anti-Theft system, the Laptop will continuously send data about its location over the internet and this is enabled by default - not everyone needs it or is comfortable with it. For some in-detail look into Computrace, read this article.
Lenovo allows you to not only Enable/Disable the features, but you can even permanently disable it. They warn you that you can never re-enable it, so I assume its wiping the option ROM. After permanently disabling both Intel AT and Computrace I didn't see any of the services that Securelist identified running.
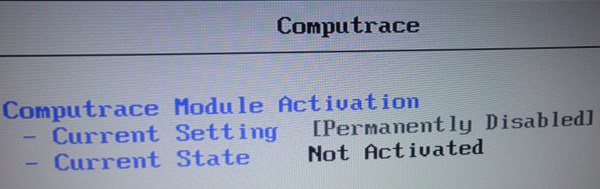
The E440 also comes with a TPM Chip, useful for Bitlocker. A Fingerprint reader is an option as well, although I ordered mine without. Both features can be disabled in the BIOS if there's no need for them.
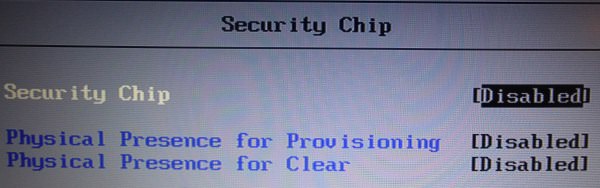
Finally, UEFI Secure Boot can be toggled, but what's even more important, you can enter "Setup Mode" which allows you to enter your own keys. This is important if you use non-Windows OS but still want to use Secure Boot.
Software
I can't really say too much about the preinstalled software. I noticed that it came with stuff already installed on it, but the first thing that I did was reinstall Windows on the new SSD.
Lenovo offers Windows 7 Professional as a BTO Option, which is great since there's no good successor to it on the market yet but they include neither installation media nor a product key sticker (UPDATE: There is a real Windows 7 Product Key sticker - it sits under the battery). I had a Win7 Professional DVD lying around from another computer and used the free MagicalJellyBean Key Finder to extract the product key from the installation.
When it comes to non-Apple laptops, you should ALWAYS install them from scratch if you want a clean Windows installation without any crap on it, but as said, I haven't done a thorough investigation on the E440 before I wiped it.
The Screen
Two features sold me immediately: The screen is Anti-Glare, and it's 1600x900 on 14". Anti-Glare used to be the default for laptop screens because it makes it better to work with, but with the influx of Entertainment-focused laptops in the late 90's, the Anti-Glare was omitted, leading to screens that have deeper blacks for games/movies but make it a nightmare to work with.
From what I can see, the screen is a TN Screen, not an IPS. This means color distortion from an angle. The E440 doesn't distort much when viewing from the side, but doesn't have a really wide vertical angle. I'm a programmer, so that works perfectly fine for me, but if you're in need of accurate color representation, don't get a TN screen.
1600x900 on 14" is awesome for me. I have enough real estate to have all the stuff open that I want and I can still read it without having to use the utterly broken Windows DPI Scaling feature. Here's a screenshot, click for full size:

Mouse-replacement - Touchpad and Trackpoint
When it comes to Laptops, there is one major issue: The Touchpad that's used in lieu of a mouse. Apple's Macbook touchpad is phenomenal, it's lightyears ahead of anything the Wintel crowd sells. The problem is that I don't really like their current lineup of Laptops, and since I don't use Mac OS X anyway (I run Windows 7 on both my main machine - a Mid 2010 Mac Pro - and on my MacBook Pro before I sold it) I could safely look at all the options on the market.
One of the key reasons to go Lenovo ThinkPad was because of their TrackPoint, a little "joystick" sitting in the middle of the Keyboard (between G, H and B keys) that can be used to move the mouse pointer. It takes a little bit to get used to, but then it's pretty awesome and precise. The main touchpad is acceptable as well, but the Synaptics TouchPad driver isn't as good as what Apple offers in Bootcamp. Specifically, scrolling with two fingers has a slight delay before it returns to normal operation and doesn't work in all apps (e.g., in Steam it doesn't really emulate a scroll wheel).
The Keyboard

The Keyboard itself is awesome, the chiclet style and size of the keys makes typing straight forward and easy, I didn't have any issues hitting the right key (and only that key, not some neighboring keys as well). What has really sold me is the fact that there are dedicated PageUp/Down and Home/End/Insert/Delete keys. That actually took me a whole to get right, because after working on a MacBook Pro for a long time, I'm so used to Fn+Up for PageUp or Fn+Left for Home that I needed to retrain myself for this keyboard, but now it's awesome for programming. The one thing I wasn't willing to relearn though is the positioning of the Fn and Ctrl keys - Ctrl is the bottom-left key, Fn is to the right of it. Lenovo has acknowledged this and offers a BIOS option to swap Ctrl/Fn to their correct order.

The F-Keys default to their alternative mode, where F1 is "Mute" and F5 is "Brightness Down". But again, there's a simple way to change that, Fn+Escape switches it around so that F1 is F1 and Fn+F1 is "Mute". This setting persists across restarts, which is awesome!
It's definitely one of the best Laptop Keyboards I worked with.
Conclusion
Lenovo did a spectacular job on the BIOS. It's a bit sad that this has to be explicitly pointed out, but they allow you to toggle or tweak almost every feature the Laptop offers. I assume that by virtue of being a business laptop, they assume that they are selling to IT System Administrators.
The Laptop isn't too heavy and has a good battery lifetime with the 62WH battery - I can go through a whole day of working without any issue. I do not know if the 7200 rpm hard drive would draw a noticeable amount of power as I immediately replaced it with an SSD. Despite being made out of plastic, it doesn't feel cheap, although of course it's not in the same league as Apple's unibody.
The touchpad cannot hold a candle to Apple. But when it comes to PC touchpads, it is definitely workable. The Trackpoint stick is a great way to control the mouse pointer as well if you're used to it. Tap to click works pretty well, although there's no "tap bottom right corner" to right click (you can set it to "tap with 2 fingers to right click").
Overall, I'm very pleased with the E440 once it finally showed up on my doorstep. For the money I got almost all the specs that I wanted without having to make compromises, although of course I'm not factoring in the $200 SSD that I still had lying around. But even for the $1000 that it would cost, it's worth the price for me.
Putting in the SSD and RAM was easy - unscrew three screws at the bottom (with a normal screwdriver, not some special nonsense), unclip the plate the screws are holding, voila, HDD and RAM is right there. This is how PC Laptops are done since forever, and this is something I missed on my MacBook Pro where changing the Hard Drive was a loathsome operation. Also, the battery is a removable part, as it should be.
I like it. A lot.
April 6th, 2014 in
Hardware | tags:
fluff
Here's a picture of my one remaining Windows XP machine:

You may think "Whoa, that's a whole bunch on obsolete technology!", and you would be right. But as a hobbyist and hardware hacker, and this stuff is my hobby. Now, despite being NT-Based, Windows XP still allowed enough access to make this stuff work. Specifically, it allows installation of unsigned drivers out of the box.
Driver signing may or may not have real security benefits - assuming that the signing certificate isn't compromised, which given the current flood of severe security bugs is hard to believe. But it's also an unnecessary stopgap against people who know about computers. Basically, the computer is mine, waiting for my command. I paid for it, and I expect the machine to do what I want. And if I'm okay with a driver, I don't take "Sorry, can't do that because it isn't signed as an answer" - I demand the ability to say "Shut up and install the driver" and Windows XP still offers that, while newer versions of Windows don't.
Well, actually, newer Windows versions do apparently offer a way to disable driver signing. The problem is that it's problematic on x64 and that Windows displays annoying nag messages. Also, I had some issues with Sound Drivers, although I don't want to exclude the possibility of me making a mistake (there are also rumors that signed Audio/Video drivers are required for DRM reasons, but I haven't found hard evidence on that).
In any case, if you are a hobbyist that requires a good amount of control over your system, Windows XP is the last Windows Version that allows that control. Linux might be an option if your applications run on it.
That being said, this is my only WinXP machine, my main OS these days is Windows 7. In fact, I just configured a new Laptop (Lenovo E440) with Windows 7. I am very aware of the genuine improvements that Microsoft made with Windows 8 (The task manager is much better, still no Process Hacker though, and seeing statistics on file copying is nice), but even though I tried to give it a chance for several months on both 8 and 8.1, it's simply not a good operating system. It's an awkward fusion of two completely independent systems that just suck on a non-touchscreen PC, it looks ugly in a lot of places, driver compatibility is abysmal (I had to use the Windows 7 WiFi driver on my Lenovo Q190 because neither the official 8 nor 8.1 driver worked) and it simply broke games - Windows 8.1 is actually much, much worse than 8 was. It is simply not well executed, not stable, and not ready for use. It's inferior to both ME and Vista in their first releases.
Touch screen devices are awesome if you're browsing the internet and if you like to draw. But for actual work, they are inferior to Mouse/Keyboard control. Speaking of that: When I press the Windows key in Windows 7, the start menu opens without stealing focus from my current application. In Windows 8, it's like someone explodes a flashbang, completely ripping my out of my focus. YMMV as usual, but that was the final nail in the coffin.
If Microsoft gets their stuff together and produces another good desktop OS, I'll gladly give it a shot. But right now, all signs point towards Windows 7 becoming the next XP - the eternal Windows.
March 6th, 2014 in
Development
I'm looking for a few fonts right now that can be freely redistributed. One of the sites that popped up was Open Font Library, a site that boasts logos from Mozilla and some other companies to appear credible. One of the fonts they list is Estrangelo Edessa, licensed under MIT (X11) License according to the site.
The problem is that all of my research point towards this being dangerously wrong. Specifially, everything points towards the font being owned by Microsoft, and they have their own licensing options. The TTF and OTF Files in the archive specifically mention that the font is copyrighted by Microsoft - I have found no, absolutely no evidence that the Font is in any way free. It is included with the Windows Operating System which makes it readily available, but if you need to distribute the font (e.g. as a Sprite Font for a game) to non-Windows-OS, you enter very shaky legal ground.
I am very well aware that there is a certain attitude towards downloading and using fonts that ignores all licensing concerns, and I doubt that anyone cares if you use a pirated font to print your "Yard Sale and Tom's 6th Birthday party" flyer. But if you want to distribute a font as part of a product or use them in very public publications, I highly recommend reading up on font licensing. NBCUniversal got sued at least twice over using unlicensed fonts and even though in both cases they settled out of court, it's reasonable to assume there was money involved. Rick Santorum and Microsoft also have tales to tell regarding font lawsuits.
Fonts are copyrighted computer programs, and just because some website claims that the font is "free" doesn't mean that they are right. And even with free fonts, sometimes they are only free for Non-Commercial use. Always double and triple check who the actual creator of the font is and what the actual license is.
March 6th, 2014 in
Development | tags:
fonts,
free
There is a severe SSL/TLS Vulnerability in iOS and Mac OS X (that is at least fixed in iOS 7.0.6, although not yet in Mac OS X). For a good analysis, look at this article. One recommendation that I would make to improve the code is a simple matter of naming.
Let's look at the code:
static OSStatus
SSLVerifySignedServerKeyExchange(SSLContext *ctx, bool isRsa, SSLBuffer signedParams,
uint8_t *signature, UInt16 signatureLen)
{
OSStatus err;
...
if ((err = SSLHashSHA1.update(&hashCtx, &serverRandom)) != 0)
goto fail;
if ((err = SSLHashSHA1.update(&hashCtx, &signedParams)) != 0)
goto fail;
goto fail;
if ((err = SSLHashSHA1.final(&hashCtx, &hashOut)) != 0)
goto fail;
...
fail:
SSLFreeBuffer(&signedHashes);
SSLFreeBuffer(&hashCtx);
return err;
}
As you see, the code needs to ensure that SSLFreeBuffer is called on the signedHashes and hashCtx variables, hence they are using goto all over the place. Say what you want about goto, but in absence of a built-in try..finally (there is a Microsoft extension, but, well, that's not standardized), this may be good - it's certainly common to see goto in C code, and if someone knows a good alternative, that would be a benefit for many.
My concern is that there is a label called "fail" that is also used to return success (that is, whenever err is 0).This seems like a bug waiting to happen since it's not actually failing (well, except that it's failing to fail). One idea is to make sure that fail forces a failure state, use a second label for cleanup and jump over the failure in case of success:
if ((err = SSLHashSHA1.final(&hashCtx, &hashOut)) != 0)
goto fail;
err = sslRawVerify(.....);
if(err) {
...
goto fail;
}
// If we get here without an error, we're golden!
goto cleanup;
fail:
if(err == 0) err = ERR_SHOULD_NEVER_HAPPEN;
cleanup:
SSLFreeBuffer(&signedHashes);
SSLFreeBuffer(&hashCtx);
return err;
This is still using a whole bunch of goto spaghetti, but it will make sure that fail actually fails, at least with some error state that says "The code did something it shouldn't".
There might also be a case to be made to assume that the function should always return a failure unless it's proven the verification succeeded. Right now, the function does kinda the opposite: It leaves err uninitialized then then runs it through a gauntlet of checks that bail out once err is ever not equal to zero. Bailing out early is good, but I wonder if there should be a secondary variable success that is initialized to false and only set to true in the one spot we know there's not an error.
That could be additional complexity without any real gain though. Personally, I try to write security-related code in a way where bugs tend to make valid cases fail rather than invalid cases pass (in other words: Give valid users too little access instead of invalid users too much), but that's of course easier said than done.
In any case, I highly recommend calling variables, functions, labels after what they actually do, and in this case, fail is an inaccurate label.
February 23rd, 2014 in
Development | tags:
apple
I'm currently looking into Commodore 64 game development again, and one of the interesting questions is "How to display the graphics?" The C64 has a plethora of display modes, and with the use of raster interrupts it is possible to mix the different modes to create crazy tricks. A while back, I asked a question titled "What exactly makes up a screen in a typical C64 game?" and got a good answer, but at the time I didn't really understand it. In order to really understand how a C64 screen is made up, I'm looking at a few games and describe what exactly they do. The first game I'm looking at is Maniac Mansion, undoubtedly one of the most important adventure games ever written (Random fact: I was lucky enough to finally find an original C64 version of it :))
Anyway, let's look at the first screen, the selection of kids:

This is purely done in multicolor character graphics:

Note that the program I use to rip character graphics - CharPad - makes it a bit hard for me to adjust colors, hence the palette is slightly off. Of note is Razor's hair color, Michael's Skin Color, Jeff/Sid/Wendy's Hair or Earring. It seems that Light Blue (Color 14) is the common background, Black (Color 0) and Light Red (Color 10) are the common multicolor backgrounds, and the individual Color RAM color is Yellow (Color 7) for Maniac Mansion, Sid, Wendy and Jeff, White (Color 1) for START, Red (Color 2) for Razor and Brown (Color 9) for Michael. Notice that the drop shadow for the Maniac Mansion logo is the same as the common skin color.
The white border around the selected kids is also a character. The only sprite is the crosshair, which changes into a snail when in pause mode:
The game screen looks a lot more complex at first:

The Character is made from 4 different sprites:

The VIC-II can display up to 8 sprites per scanline, so I assume that a raster interrupt is used when all 3 kids are in the same screen.
Everything else is made up from character graphics (again, slightly off due to me not fixing up all the colors):

Looking at the screen ram (using VICE's sc command) shows this:
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
ffffgfffffffghijjjjkjjjjlmgfffffffgfffff
@@@@g@@@@@@@gopqqqrstqqquvg@@@@@@@g@@@@@
|yz{gx|yz{bxg}~ !~s" !"#gxxyz{bxgyz{xx
)*@@gx)*,@+xg}~-./~s"-./"#gx)*@@+xg*@@+x
6@@@gb6@@@7xg}~a8a~s"aaa"#gx6@@@7bg@@@7b
BCCCgbBCCCDbg}~aaEFsGHaa"#gbBCCCDbgCCCDb
6V@@ex6V@@7xW}~aaXYsZ[aa"#Wb6V@@7xWV@@7x
6@@@Ab6@@@7bA}~aaa~s"aaa"#Ab6@@@7bA@@@7b
ffffgfffffffg}~aaa~s"aaa"#gfffffffgfffff
WbWbWbWbWxWbI}~JJJ~s"JJJ"#IbWbWbWbWbWbWb
QbQbQbQbQbQRQSTTTTTUTTTTTVQWQbQbQbQbQbQb
fffffffffff.......IJKLMNO...ffffffffffff
1010_0_0 ...P............... .1010101010
010.I......P^.............@.ABCD01010101
.T IcccUV.P^...............@.AWXY__0 010
ccccccc\b]^.................@.b.cccccccc
cccccccc.......................ccccccccc
WALK TO@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
PUSH OPEN WALK TO NEW KID TURN ON
PULL CLOSE PICK UP UNLOCK TURN OFF
GIVE READ WHAT IS USE FIX
Uhhh... Well, it's a bit rough for sure, but it illustrates how the screen is composed. Another thing of note is that the C64 supports two different character sets (2x256 Characters) and that the second character set consists of a common font, including the inventory arrows. This is one of the reasons that there is no text in the main game screen - they use the second (font) character set for the title line, switch to the primary set to draw the screen, then back to the secondary set for the menu at the bottom.

There may be some further tricks in some areas (e.g, I haven't checked how Chuck the Plant or the Radio in Dr. Fred's room is done) but overall this is how the game works: Sprites for the characters and the crosshair/snail, two character sets for the game screen and the menu.
February 10th, 2014 in
Games | tags:
c64,
What's on the Screen
This is Pac-Man on the Atari 2600, played on an Emulator. The game was generally seen as a horrible port of the arcade game, done under a lot of time pressure, and this video really makes it look bad. See the flickering ghosts? How could they ever release a game like that? And it's not the emulator either, hooking up a real Atari 2600 to a modern TV has the same flickering!
Now, the game wasn't great, but the sprite flickering was actually not an issue back them. You see, the Atari 2600 was very limited when it came to sprites:
[...]the video device had two bitmapped sprites, two one-pixel "missile" sprites, a one-pixel "ball,"[...]
Each Ghost is a sprite, so we'd need 4 sprites per scanline, which was simply not possible with the hardware. So the programmer did a clever trick (that was also used on other 8-Bit Consoles like the NES or Sega Master System at times): It would only draw one Ghost per screen refresh, so each ghost would only be drawn once every four frames. That explains the flickering, because Ghosts that aren't drawn are invisible.
This worked because in the old days, we had these big tube TVs that were using an electron beam firing on phosphor dots to ignite them. But what is important is that phosphor doesn't immediately go dark again when it's not hit the next time around - the dot slowly becomes dimmer until it's "off". This effect is known as "Afterglow" and is the secret to make the Ghosts trick work.
On a modern LCD display, turning off a Pixel immediately turns it off, while on an old Tube TV the image slowly fades out:

This is the magic trick - the sprites are never fully invisible on the old Tube TV, and thus they could do four ghosts on a system that could only do two sprites. With the flickering going on, it wasn't actually very noticeable either, but that greatly depended on your TV, naturally. Some newer high end ones or even computer monitors had a much quicker reaction time than the consumer TVs of the 80's.
To show the effect in a video, I hacked together a project in XNA that illustrates the effect of Afterglow vs. No Afterglow. Note the pulsing but not quite invisibility of the bottom sprite vs. the utter flickering of the top sprite - back in the day the pulsing might have been noticeable, but it's much better than the extreme flickering modern LCDs offer.
January 27th, 2014 in
Development,
Games | tags:
emulation,
retro
(For all Game Math Cookbook postings, click on the Game Math tag.)
When working with angles, I'm used to degrees. 90 degrees is a right angle, 360 degrees is a full circle. But in Game Math, Radians are commonly used. What are they, why do they exist and how would I use them?
Well, radians are derived from π (pi). 180 degrees would be 3.14.... radians, or more exactly, 180 degrees is exactly π radians. Thus, 360 degrees is 2*π, 90 degrees is π/2, 45 degrees is π/4 etc. There is a beautiful explanation (with pictures) on MathIsFun.com which should make it very clear what radians are.
What's interesting is the fact that most people think of degrees as the normal way to measure angles (because that's taught in schools) is due to some ancient way of using starts in the sky as a measurement. BetterExplained.com does a good way of explaining that.
Now, the question is: Why do Games tend to use radians instead of degrees? One explanation that I found is that the 80387 co-processor had hardware-operations for calculating sine and cosine, but it expected radians:
4.6.1 FCOS
When complete, this function replaces the contents of ST with COS(ST). ST, expressed in radians, must lie in the range 3i3 < 2^(63) (for most practical purposes unrestricted). If ST is in range, C2 of the status word is cleared and the result of the operation is produced.
At that time, the x87 co-processors offered pretty significant speed boosts and from what I've seen, it's still widely used (e.g., the .net JITter translated Math.Sin() calls to an fsin instruction at least in 2004). I've opened a question on GameDev StackExchange and the answer (and DMGregory's comment) seem to make a clear case for the question being wrong: We shouldn't ask "Why use radians" but rather "Why would you ever use degrees?".
December 22nd, 2013 in
Development | tags:
game math
It's been fifteen years since I had math in school, and even then trigonometry was barely just touched on. Every time I try to do game development though, I'm hitting a brick wall because people throw around concepts like tangents, radians and square roots of things like it's nothing and I completely forgot about all of that. Wikipedia isn't really that helpful because it explains the concepts from a math perspective which means it's dry, complicated, and doesn't answer the question "What would I use this mathematical concept for?". So for my own sake, I'm blogging about a game problem and how to solve it with math in a way that I can understand.
A note on Vectors: I use "vector" for a collection of 2 points (since I'm dealing with 2D here). In Mathematics, vector has very well defined meanings, but here it's just a X and Y value and a vector might both define a Point in space or an adjustment that's done over time.
Movement from A to B over time
Possibly the earliest (and easiest) problem is movement of something from A to B over time. I know that my object can move at 3 units per second (this is something I made up for the game, you'll have to figure out what speed you use in whatever game and coordinate system you use). I know where it is right now (A at 4,4) and where I want it to eventually be (B at 9,6), but how do I get there?
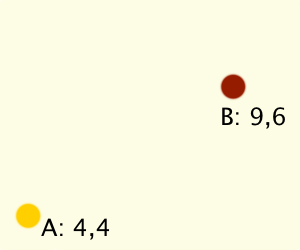
What we need is a movement vector, that is a set of X/Y values to add to A over time. What does this mean? Let's say that our movement vector is 0.6,0.4 just for the sake of the example. That means that after 1 second, A should be at 4.6,4.4. Then, a second later it would be at 5.2,4.8 and so on. The movement vector is called velocity because it doesn't describe a point in space but a magnitude of which a point gets shifted over time.
How do we find out the velocity? First, we need to know the difference between points A and B so that we know what we have to cross. Let's call this the difference vector, and it's calculated by B.X-A.X,B.Y-A.Y or in the example, 9-4,6-4 which results in 5,2. That's neat, but that's the complete distance I have to cross it doesn't tell me how much to move over time.
Here's the point I struggled with for a long time: Normalized Vectors. People call this the unit vector usually without going to deep into it. The textbook definition: A unit vector is a vector of length 1. What does that mean? For a long time, I thought that means that X + Y have to equal 1. The difference vector above seems to be 5+2 = 7. Why do I need to have a vector of length 1 and how to I turn my vector of 7 into a vector of 1? Just subtract X/Y by 7 to get 0.71,0.29?
First off, the length of the difference vector is not 7. This was a mistake I made for a long time. Rather, the length of the vector is the hypotenuse of a right triangle with origin 0,0 and points at the X and Y coordinates. Let's just quickly go over the parts of a right triangle (image courtesy of Wikipedia):
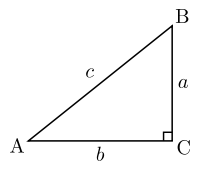
The Hypotenuse c is the longest side and is the one opposing the right angle. Side a is the adjacent while side b is the opposite. Angle B seems to be the source of the naming since side b sits adjacent to it while side a is on the opposite.
Point A is 0,0. Point B is my difference vector, 5,2. Point C is chosen by us to sit at 5,0 so that we get a right triangle like this:
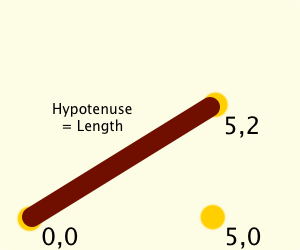
This is where the pythagorean theorem comes in, which defines that a2 + b2 = c2. We want c, and we have a (2) and b (5). Let us calculate c2:
- a2 = 5 * 5 = 25
- b2 = 2 * 2 = 4
- c2 = 25 + 4 = 29
Getting c is now simply the square root of c2, which is 5.385164807134504 or 5.39 for short.
The length of the vector 5,2 is 5.39, not 7. Because it takes 5.39 units to cross the distance from 0,0 to 5,2 or from 4,4 to 9,6. Because if the length were 7 it means you would first walk the X-Axis for 5 units and then the Y-Axis for 2 Units, when you could just cross diagonally.
Quick recap:
- Source (A): 4,4
- Destination (B): 9,6
- Desired Speed: 3 units per second
- Difference: 5,2
- Length of Difference: 5.39
- Velocity: ???
So how do we get the velocity and what does this stuff have to do with normalized vectors? As said, a normalized vector is a vector of length 1, and we can get the normalized difference vector by dividing both 5 and 2 by 5.39 which gets us a vector of 0.93,0.37 (which, ignoring a rounding error for the sake of the blog post, has a length of 1 = sqrt(0.932 + 0.372)). We can now multiply this with the desired speed - 3 - to get the Velocity: 2.79,1.11 per second.
- Source (A): 4,4
- Destination (B): 9,6
- Desired Speed: 3 units per second
- Difference: 5,2
- Length of Difference: 5.39
- Normalized Difference: 0.93,0.37
- Velocity (=Change applied to A every second): 2.79,1.11
This would then be multiplied with the frame delta time to get the amount of movement in a frame (so in a 60 fps scenario you would multiply it by 1/60 = 0.016666...).
I still haven't explained the use of a normalized vector. I think that Gamedev.net has done a good job explaining it, but in my own understanding: The difference vector has a magnitude of it's own - with a length of 5.39 it would mean that my object would move 5.39 units per second. So normalizing a vector to me is an application of the rule of three. How do I get from 5.39 units per second to the desired 3 units per second? By going down to 1 unit per second:
- 5.39 = 5,2
- 1 = 5/5.39 , 2/5.39 = 0.93 , 0.37
- 3 = 3*0.93 , 3*0.37 = 2.79 , 1,11
December 21st, 2013 in
Development | tags:
game math
Companies around the world seem to love Internet Explorer. It's the number 1 corporate browser and every web designer has horror stories to tell about how many workarounds they have to put in to support IE 6-8 and how the update cycle is not only way too long but also how new versions don't help with companies that don't want to update. Firefox and Chrome release new versions every few weeks, constantly innovating and improving, while Internet Explorer has to be supported for years.
Why don't companies switch away from Internet Explorer and use modern browsers like Firefox or Chrome?
Now, I can't speak too much about Firefox (apart from the fact that maybe the lack of an official integration into Windows Systems Management features is an issue - FrontMotion is an alternative, but it's not officially Mozilla) but as a corporate developer I can definitely speak why Chrome is not a good browser for corporate environments running Windows: Google has a long history of shipping broken releases of Chrome.
Let's back this up with facts, shall we?
One of our internal websites has an <img> tag which references an image on another internal website, both websites are behind NTLM authentication. The simplest thing in the world: The Image gives an auth challenge and the browser answers it, downloads the image and displays it. Works in Internet Explorer since forever, works in Firefox (may display a login prompt if the other website isn't in the list of trusted urls), used to work in Chrome.
Except that it no longer works, Chrome 30 doesn't load the images anymore. The main bug report for this is 303046 from October 2. Chrome 31 was released on November 12, 2013 and fixed that - 41 days turnaround time.
Chrome 23 had a bug where a failed Kerberos Auth would not fall back to NTLM. Kerberos wasn't even supported in the beginning, I think it took until version 6 or 7 and they had to solve some issues involving proxies after that.
Here's a fun one in Chrome 19 (well, duplicate of this one): A POST request with an attachment to an NTLM Authenticated site would destroy the attachment. That might even have been a regression since a similar bug was reported in Chrome 7.
Chrome 5 would fill up our IIS logs because it was requesting the favicon.ico. Thousands of times, every few milliseconds while the user was on the page.
Each of these bugs were in a stable build that was pushed to users through automatic updates, and sometimes these issues had been reported in the Dev/Canary build weeks in advance yet still made it all the way through the release process. That in turn means that it would take weeks before a fix would be available in another stable release.
Chrome might be a great browser if you're not in a corporate environment or if your corporate environment doesn't run on Windows. But if you are a Windows shop that uses NTLM authentication, Chrome just isn't stable enough to use, unless you're willing to have some of your internal sites broken for several weeks every time Chrome ships another NTLM-related bug in the stable release. It seems that Google's priority is the fancy new HTML5 stuff, not rock solid corporate NTLM support.
Feel free to complain about Internet Explorer as much as you want, but please don't wonder why companies aren't migrating to other browsers when other browsers simply don't support corporate environments with their specific management/policy and authentication needs.
November 1st, 2013 in
Applications | tags:
rant