When it comes to PC Engine CD-ROM² System Card compatibility, the answer is usually "The Super System Card 3.0 will play every game... except for one". That exception is 1989's PC Engine CD-ROM² release of Altered Beast (Juuouki), which will hang once you transform into the beast and the game tries to load a new chunk of the level. The game is not frozen - music still plays and controls are still responsive, it just does not scroll any further on any System Card other than 1.0.
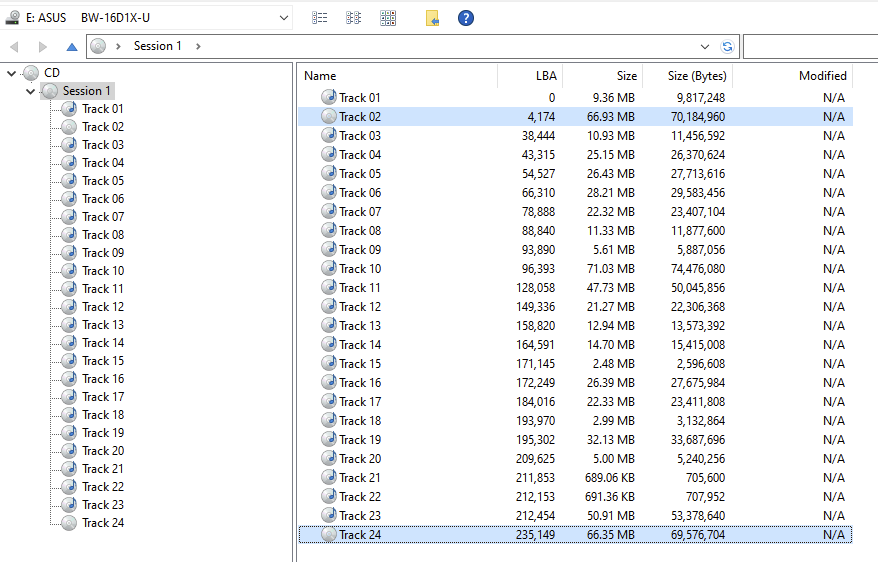
If you look at the layout of a PC Engine CD-ROM² game, you will probably find a disc that has two data tracks:
I thought this was pretty unusual - as someone mostly familiar with home computers and later CD-based consoles, I usually expect a single data track as Track 1 and optional Audio tracks afterwards.
Why does the CD start with an audio track?
Seeing the data track be Track 2 does make sense to me given how early in the "CD as data storage" lifecycle it was: Track 1 is an audio track warning people to not play the Disc in a CD Player because playing a data track is very unpleasant and can (allegedly) damage equipment.
The PC Engine CD-ROM² consists of a HuCard containing a BIOS, which interfaces with the actual CD-ROM drive and serves as a bare-bones operating system of sorts for CD-ROM games.
Like all HuCards, the System Card is mapped to the $E000-$FFFF memory range on startup (MPR#7 = $00), and developers should not change this when calling BIOS functions since the code assume that base address. The BIOS also assumes/requires that MPR#0 is $FF and MPR#1 is $F8 to map the I/O and Work RAM to the beginning of address space, which is standard anyway.
When it comes to playing fighting games or certain arcade/MAME games, an Arcade Stick can be nicer than a gamepad. You can really mash the buttons and yank the lever (that’s the technical name for the actual stick).
There are many that you can just buy, and that’s probably the preferred choice. Hori has long been a trusted brand, I actually own a Victrix Pro FS, the Hitbox is getting a lot of buzz because it’s all buttons, no lever, and I’m currently waiting on a Snackbox Micro because of it’s size. Seriously, it’s tiny.
Most ATX Mainboards have somewhere between 3 and 5 PCI Express slots. Generally, an x16, x8 and some x1's, but if you have e.g., a Threadripper X399 board you might have several x8 and x16 slots.
But what if you want more devices than you have slots? Let's say you want a whole bunch of M.2 NVMe drives, which are only x4 each. Ignoring any motherboard M.2 slots, you can use adapter cards that just adapt the different slots: