Over the last couple of weeks, we've been working on changes to our SAML 2.0 Authentication on Stack Overflow Enterprise. This was required to better support scenarios around signing and encrypting SAML Requests and Responses, and as such, a lot of the work was centered around XML Security, specifically the SignedXml and EncryptedXml classes.
Now, one thing I can say for sure about SAML 2.0 is that every Identity Provider implements it slightly differently, causing XML Validation errors or CryptographicExceptions somewhere deep in the code. So, how can we properly debug and fix this?
The first option is to Enable Symbol Server support in Visual Studio. This gives you .pdbs for .net Framework code, but because the Framework is compiled in Release mode, some code is inlined or otherwise rewritten to no longer match the exact source, which makes following variables and even call stacks really hard the deeper you go.
Another option is to check out the .net Framework Reference Source, also available on the easy to remember http://sourceof.net. This is the actual source code of the .net Framework, which allows at least reading through it to see what's actually going on, at least until you hit any native/external code. You can even download the sources, which not only allows you to view it in Visual Studio, but it also allows you to compare implementations across Framework versions to see if anything changed. (The code on the website is always only for the latest Framework, which is 4.7.1 at the time of writing. If I need to see how something was implemented in 4.6.2, I need to download the sources)
Another thing that we can do with the reference sources is to put them into our project, change namespaces to avoid ambiguity, and then use our private copies of the implementation.
This is a huge help for several reasons:
- We can step through actual code, no compiler symbols or weird abstractions, it's actual code.
- Since we can compile in Debug mode, we don't have to worry about optimizations making the debug experience much harder.
- Breakpoints work properly, including conditional ones.
- If we have a hypothesis about a cause of or fix for an issue, we can make source code changes to verify.
Now, there are two problems with Framework Sources. First off, because Framework code can refer to protected and internal methods, we might have to either copy a massive amount of supporting code, or implement workarounds to call those methods that are inaccessible to us (there are 79 files in my private copy of SignedXml/EncryptedXml). But the real showstopper is that the license doesn't allow us to ship Framework code, as it's only licensed for reference use. So if I found a way to fix an issue, I need to see how I can make this work on our side of the code, using the actual .net Framework classes.
Now, if we really don't find a way to solve this issue without needing to modify Framework code, a possible option are the .NET Core Libraries (CoreFX) sources, because that code is MIT Licensed. It's a subset of the .net Framework, but due to the license, anything that's there can be used, modified, and shipped by us. This is a bit of a last resort, but can be preferable to worse workarounds. I can not understate how awesome it is that Microsoft releases so much code under such a permissible license. It not only makes our life so much easier, but in turn it benefits our customers by providing a better product.
In the end, we could resolve all issues we've seen without having to modify framework code after why understood exactly where (and why!) something was failing, and our SAML 2.0 implementation got a whole lot better because of the availability of the source code.
November 4th, 2017 in
Development
It's been a few month since I released Simplexcel 2.0.0, which was a major change in that it added .net Standard support, and can be used on .net Core, incl. ASP.net Core.
Since then, there have been a few further feature updates:
- Add
Worksheet.Populate<T> method to fill a sheet with data. Caveats: Does not loot at inherited members, doesn't look at complex types.
- Also add static
Worksheet.FromData<T> method to create and populate the sheet in one.
- Support for freezing panes. Right now, this is being kept simple: call either
Worksheet.FreezeTopRow or Worksheet.FreezeLeftColumn to freeze either the first row (1) or the leftmost column (A).
- If a Stream is not seekable (e.g.,
HttpContext.Response.OutputStream), Simplexcel automatically creates a temporary MemoryStream as an intermediate.
- Add
Cell.FromObject to make Cell creation easier by guessing the correct type
- Support DateTime cells
- Add support for manual page breaks. Call
Worksheet.InsertManualPageBreakAfterRow or Worksheet.InsertManualPageBreakAfterColumn with either the zero-based index of the row/column after which to create the break, or with a cell address (e.g., B5) to create the break below or to the left of that cell.
Simplexcel is available on Nuget, and the source is on GitHub.
Here are three power cables. Do you see what's different between them? Hint: One of them is a serious fire hazard.

I don't know about you, but I have a box full of computer cables that I amassed over the years, and whenever I need a cable, I grab one from the box. There are plenty of power cables in that box, and I never thought twice about which one to use for a PC. Until one episode about two years back. The PC that I was using was a real high end killer machine - I don't remember the exact specs, but I know that it was a $1000 Intel CPU, so I believe it was a Core i7 Extreme, paired with a high end Geforce card (I believe a GTX 660 or 680). I was playing a game, when suddenly I heard a popping noise and saw sparks falling to the ground. Like, literally sparks. At first I thought that the power supply blew up and tried a new one. After some more trial and error, we finally found out that is was the power cable that melted and sparked.
I had never seen that happen before. I knew that the super high end power supplies had a different connector (IEC 60320 C19 instead of C13) - but I didn't think that there was any difference for regular power supplies.
Turns out that the thickness of the wires inside the cable matters a lot. This makes sense: Electricity going through a wire heats the wire up - the more power, the warmer it gets. If the wire isn't thick enough, it will literally melt and can then cause a short, or like in my case, sparks (and potentially a fire). One of the standards used for wire thickness is called the American wire gauge, or AWG for short - you may have seen this used for speaker wire. A cable that you buy will have a number - like 18 AWG - which describes the thickness. Lower numbers are thicker, so a 14 AWG wire is thicker than an 18 AWG wire (do note that there is a difference between a wire and a cable - a cable is one or more wires plus insulation and connectors).
In the above picture, there are 14, 16 and 18 AWG cables with C13 connectors shown. Monitors tend to ship with 18 AWG cables, which is why I have a bunch of them. But 18 AWG power cables are not suitable for powerful PCs. They might be suitable for lower end PCs (that can safely run on a 450W or less power supply), but even a single 95W CPU and 8-Pin powered Graphics Card (like a GTX 1080) might draw too much power for the cable - a fire hazard waiting to happen. The cables will have their gauge written on them, or etched (which is harder to read).

Now, before you go and buy a bunch of 14 AWG power cables, do note that the thicker a wire is, the stiffer it is. 14 AWG cables are generally very stiff, so if the PC is close to a wall or the cable needs to make a bend for another reason, you might be putting a lot of force on the power supply connector. In general, 16 AWG should be perfectly fine to at least 850W - possibly more.
July 29th, 2017 in
Hardware
Update 2017-07-25: I found a case, see at the bottom.
My home setup is a bit of a mess. That's mainly because I haven't properly planned out my needs, and now I have a Simple File Server that doesn't accommodate my future growth, an old server to run VMs on, and some random assortment of hardware to do backups on.
So, I'm now making a list of my actual needs to build one new server to rule them all, sometime in 2018. The list of needs is fairly short:
- Enough CPU Power to run about 6 VMs
- Space for an ATX motherboard, to not limit options even if I end up with a Micro ATX board
- ECC RAM
- Enough disk space for my stuff
- Redundancy/Fault Tolerance for my disks
- Ability to do proper backups, both to an on-site and an off-site medium
- Low Energy Use
Most of these requirements are fairly straight forward: For the CPU, a Xeon D-1541 (e.g., on a Supermicro X10SDV-TLN4F-O) or a Ryzen 7 PRO 1700 will do fine. For the hard drive, using my existing WD Red 3.5" drives gives me the storage. After considering RAID-5, I'm gonna pick up a LSI Logic SAS 9211-8I controller to do RAID 1E instead, with RAID 10 being a future option.
The real question is though: Where to put all that stuff? That led me down to the rabbit hole of finding a server case. The needs seemed simple:
- Space for at least 4x 3.5" drives (ideally 8) and 2x 2.5" drives (ideally 4)
- Power Supply on top, so I don't have to worry about overheating if putting the PC on the floor
- Don't look like crap. If possible, no Window, no lit fans, not designed like 1960's Russian military hardware
- Absolutely no tempered glass. If I can't avoid a window, it needs to be plastic/plexiglass.
- Want: Ability to hot swap at least some of the drives, so some backplane
- Ideally $150 or less
Now, the "don't look like crap" part is, of course, highly subjective. Still, I'd definitely prefer the look of a Corsair Carbide 100R over their Graphite 780T. The power supply positioning changed from the top to the bottom in recent years. This is because a modern CPU and GPU produce a lot of heat, so the old way of "have the PSU suck out the heat" no longer works well. Also, water cooling isn't super-niche anymore, so radiator space is needed.
I'd like to hotswap drives, so one of my ideas was to look at some rackmountable case, but in that price range, there isn't much. I found the Norco RPC-4308 which would be pretty awesome, if not for a small detail: The power connector on the SATA Backplane is a 4-Pin Molex connector. Now, while there is a problem with Molex to SATA Power Adapters catching fire, this is not a concern here as the power is properly routed through the backplane. No, my concern is that Molex Power is not SATA compliant. SATA Power is a 15-Pin connector:
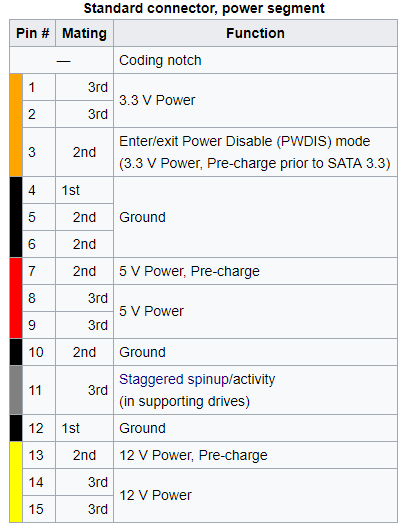
Now, the fact that there are 3 pins each for 5V and 12V isn't so much a problem (that's more a side effect of how thin the pins are and concerns sending enough current over one of them). The problem is rather that some parts are completely missing. There's no 3.3V power, no staggered spinup and no Power Disable with a Molex adapter. Arguably, 3.3V isn't needed by most drives, and power disable is almost an anti-feature outside the data center. Still, the question is: Why invest into a system that isn't fully compliant?

I haven't seen any other rackmount cases with hotswap trays that fit the price range. There is a tower case - Silverstone CS380 - that looks awesome, but also suffers from the Molex power. Next up was looking at 5.25" cages that hold up to five 3.5" drives. There are some nicely priced and not too shabby looking ones out there (e.g., Rosewill's RSV-SATA-Cage-34, but once again, buyer beware: Molex power, so that's a no for me. I am currently looking at Silverstone's FS303, FS304 or FS305. I'm not sure if putting five 3.5" drives in three 5.25" slot is a bit too closely packed, even with the low-power WD Red drives. But even ignoring the FS305, I could get six drives in four slots, or four drives in three slots, so that's pretty good.

This now leads to the next problem: Cases with 5.25" slots are becoming rarer and rarer. This makes sense, since many people don't even have optical drives anymore, and those that do only need one bay. I need at least four, better five or six. So, how many PC Cases are there that...
- Have four to six 5.25" bays
- Have the power supply on top
- Don't look like crap
- Don't cost more than about $150
- Can fit an ATX mainboard
Spoiler warning: Almost none. I spent quite a bit of time looking through the offerings on Amazon and Newegg and on many manufacturers websites, and it seems that modern day gamer-cases and really cheap mini tower cases have completely replaced everything else on the market. Now, there are a few cases for Mini ITX boards that are interesting, like the Silverstone DS380, which seems like a popular NAS case these days. Still, my goal is to not compromise unless I really have to.
I'm still researching, but here's my current shortlist:
- Lian Li PC-8N - discontinued, but still available on Newegg for about $100. 4x 5.25" bays, PSU on top
- Antec NSK4100 - discontinued, but still available on Newegg for about $50. 3x 5.25" bays, PSU on top
- Corsair Carbide 200R - about $65, my choice for my own PC, 3x 5.25" bay, PSU at bottom
- Rosewill Legacy QT01 - about $100, 3x 5.25" bay, bottom PSU
- Fractal Design R5 - about $120, gorgeous case, but only 2x 5.25" bays, so I'd have to seriously consider if I really want hotswap
- Cooler Master N400 - about $60, only 2x 5.25" bays and bottom PSU, but looks pretty nice, like a workstation
- Cooler Master CMP350 - about $85, 4x 5.25" bays, top mounted PSU, incl. 500W PSU, seems discontinued
- APEVIA X-Cruiser3 - about $70, 5x 5.25" bays(!), and the design should be good for some social media points
- Buying something used - especially old tower servers or workstations. Don't really want to do that, I've learned that name-brand complete systems usually mean some compromises in case design that I don't like
If I go with a case that has the PSU at the bottom, I'd have to consider a PSU that has the fan in the back or can be mounted with the fan pointing into the case. There aren't many PSUs with a fan in the back left, one option is the Antec EA-380D Green (which has 5x SATA connectors).
It definitely seems harder than it should be to build a whitebox server these days than it used to. Sure, the components are cheaper and more powerful than ever, but it seems that cases have stopped serving the market. I can see why people would rather buy a Synology NAS, or get some old rackmount server for cheap (Dell's R720 should really come down in price now as thousands are being replaced), or don't care about hotswapping, but still, it feels like the PC case market has regressed since the legendary Chieftec Dragon (which were also sold by Antec under the SX name) were every enthusiasts choice.
Maybe it's indeed a sign of the times, where the real innovation happens in the Mini-ITX and gaming spaces, while everything else becomes a specialized device offered by someone.
Update 2017-07-25: I found a Thermaltake Urban S41, which hits most of the things I want. It looks nice and clean, it has 4x 5.25" bays, 5x internal 3.5" bays, and a even a temporary hotswap bay on top. There is plenty of cooling, with a 200m fan on top, 120mm fans in the front and back, and an optional 120mm fan at the bottom. The Power Supply is mounted at the bottom, but the case actually has feet that elevate it quite a bit above the floor. Of course, like all nice tower server cases, it is discontinued, but Amazon still had a few for $100.

I'll add an ICY DOCK FatCage MB153SP-B, which houses 3x 3.5" SATA drives in 2x 5.25" slots. I might either add another one of those, but I'm also seriously considering 2.5" Seagate BarraCuda drives. They go up to 5 TB on 2.5" (at 15mm height), for a similar price as 3.5" IronWolf/WD Red. I'm not sure if using a non-NAS drive is a good idea, but then, vibration/heat/power usage isn't really a concern with these drives. In that case, I'd likely use an ICY Dock ToughArmor MB994SP-4S for 4x 2.5" in 1x 5.25", but it'll be a while before I need to think about that. Who knows, maybe by then there will be 2.5" Seagate IronWolf, or a 2.5" WD Red bigger than 1 TB (I run two of their WD10JFCX in a RAID-1 currently).
July 24th, 2017 in
Hardware
A while ago I put up a post showcasing adventure game GUIs, without really going into much details about them. But if you want to make your own adventure game, one of the first questions is how you want to control it. And that means, deciding how many Verbs there should be. If you ask "old-school" gamers, you will hear a lot of complaints that modern games are "dumbed down", while game designers talk about "streamlining the experience" - both positions have some truth to them, because it is important to differentiate between complexity and depth.
Let me make a non-adventure game related example: The game of Chess. The game isn't terribly complex - there are only 6 different pieces, and only a few special rules. However, the game possesses a great depth due to the many different options to play it. The game of Go is even simpler, but comparable to Chess in its depth.
Simple/Complex describes the amount of rules/actions to do, while shallow/deep describes the combinations you can achieve throughout the game. Which brings us back to adventure games. Have a look at Maniac Mansion:

There are fifteen verbs available. If you play the game, you will notice that you use verbs like "Use" and "Give" quite a few times, while "Fix" is used possibly only once or twice during a play-through, if at all. There is complexity, but do "Unlock Door with Key" or "Fix Phone with Tube" really add more depth than "Use Key on Door" and "Use Tube on Phone"?
I'd like to quote Goldmund from a thread on the AGS Wiki:
I click "use" on a furnace and I have no idea whether the protagonist will open it, push it, sit on it, piss on it, try to eat it... Of course, there are GUIs with more detailed actions, but still it's nothing compared to the Richness of Interactive Fiction. In IF you really have to think, not just click everywhere with every item from your inventory. The solution could lie in the text input, like it was done in Police Quest II
The problem with that is that it's not just a matter of thinking but also a matter of creating enough content. Having a lot of different verbs - or even the mentioned text parser - means that the game needs to have a lot of responses for invalid actions, or risk boring the audience. If I can "kick the door", I should also be able to "kick the mailbox", "kick the window", "kick the man" and get a better response than I can't kick that. Otherwise, you add complexity, but not any perceivable depth and the game is back in "guess the parser" mode.
LucasArts decided to trim down the verb list to nine in the nineties - then even changed the original Monkey Island from twelve Verbs on the Amiga to nine Verbs on DOS (removing Walk To, Turn On and Turn Off).


Removing Verbs removes complexity, but it doesn't have to mean that it removes depth. Depth is created by meaningful interactions of the verbs you have. This means that you should create a lot of dialogue - if I push something I can't push, having a more specialized message than "I can't push that" goes a long way, but that's still not actual depth. Actual depth stems from the ways I can solve the game. Do I have to solve the puzzles in order or can I pick which ones I solve when? And are there multiple solutions? Can I Use golfclub on Man to solve the puzzle by force, while also having Give golfclub to Man in order to bribe him as an alternative option?
A lot of games these days have a simple two verb system - "Interact" and "Look".

These games work nicely with a mouse but also on a tablet (where "Look" is usually a long tap). A lot of the puzzles are inventory or dialogue puzzles, which may make these games more "realistic" (they mirror real world problem solving closer), but also are often shallower. Often, there is only one path through a dialogue tree, or one inventory item that works. I can use hammer on nail, but usually not use screwdriver on nail or use book on nail - even though these are valid real world options in a pinch. And for dialogues, often there are only two outcomes, "fail" and "pass". The bouncer in Indiana Jones and the Fate of Atlantis is one exception that I can think of, where dialogue can lead to him letting you in, him fighting with you, or him dismissing you.
In the end, it's important to strike a balance between usability, immersion, and design complexity. Especially if you add translations and voice acting, having more responses and possible solutions increases the required time and money, just to create content players may never see. On the other hand, having more variety and truly different solutions makes the game feel a lot more alive and higher quality.
And that's one of the reasons I still think that Indiana Jones and the Fate of Atlantis is the perfect Point and Click Adventure.
June 28th, 2017 in
Adventures
In my earlier post about my new file server, I talked about setting up a backup strategy. Now, my first attempt was to use a ASUS Tinkerboard or Raspberry Pi 3. This attempt failed, and I'd like to go over why, so that future readers don't make the same mistake.
The Theory: Desired Setup
Here's my desired backup strategy:

As you see, the Tinker Board was supposed to be the local backup server, that is, the server that holds backups of all the main data. From there, I want to upload to Backblaze's B2 service.
Bottleneck 1: Multi-Core CPUs don't really matter for SFTP
My initial plan was to use the SSH File Transfer Protocol (SFTP). After all, the Tinker Board with its 1.8 GHz Quad Core CPU should do well, right? No, not really. The thing is that SFTP doesn't seem to parallelize well - it uses one Core to the max, and no other.
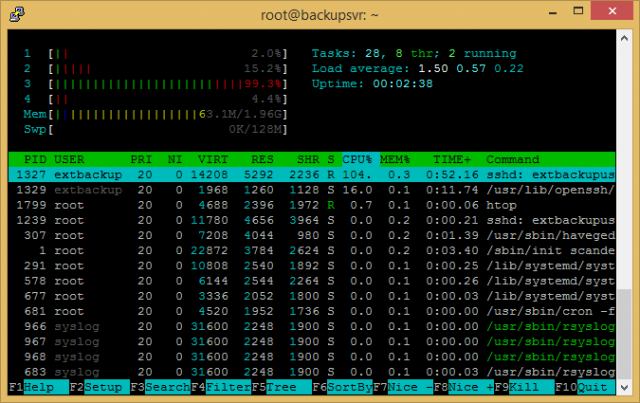
Whether this is a limitation of the protocol, or a limit of OpenSSH, I don't know, but I just couldn't get good speed over SFTP.
Bottleneck 2: USB 2.0 is just not very fast
Now, this one is a bit of a "well, duh!" issue, but I initially didn't really consider that USB 2.0 is capped at a theoretical max of 480 MBit/s, which is 60 MB/s. So even after switching from SFTP down to SMB or unencrypted FTP, I wasn't reaching more than about 45 MB/s, even though the hard drive itself can do much more. This would mainly be a problem for the initial backup (~300 GB) and for restores though.
Bottleneck 3 (Raspberry Pi only): Slow Ethernet
On the Raspberry Pi, the Ethernet is only 100 MBit/s, and connected via USB, thus sharing bandwidth. On the ASUS Tinker Board, the Ethernet is a dedicated Gigabit Ethernet controller, and thus doesn't share bandwidth.
A lot of boxes and cables, for a lot of money
This one is subjective, but my setup was 1 ASUS Tinkerboard with Power Supply, connecting to a USB Hard Drive which also has its own power supply. It looked messy, and also wasn't really cheap. For $102 ($60 Tinker Board, $14 Case with Fan, $8 Power Supply and $20 USB Drive Case), it's cheaper than most anything else. For example, a $55 Board with 10W CPU, $40 case, $20 Power Supply and $23 RAM would've been $140, but likely much faster.
Going with a Mini-ITX instead
I'll have a bigger blog post about the actual implementation later, but in the end I re-used my previous Mini-ITX box which has proper SATA for full speed hard drives and performs much better.
I do want to say that both the Raspberry Pi 3 and the ASUS Tinker Board are awesome little boards - especially the Tinker Board impressed me. But in this case, I tried to use them for something they are just not good at, and ended up wasting a bunch of time and money.
June 12th, 2017 in
Hardware | tags:
backup
Tresor is a .net library (.net 4/netstandard 1.3 or newer) to generate passwords in a deterministic way, that is, the same inputs will yield the same outputs, but from simple inputs (Like the service name twitter and the passphrase I'm the best 17-year old ever.) you will get a strong password like c<q_!^~,'.KTbPV=9^mU.
This helps with the behavior of using the same passphrase for multiple sites, but is also not reliant on a password vault that you don't always tend to have with you (e.g., because it's a file on your computer and you're on the road) or requires you to trust a cloud-service to securely keep your data.
Internet Websites get compromised all the time - so frequently that haveibeenpwned.com has been created for people to get notified whenever their email address shows up in a data breach. Troy Hunt has an amazing blog about web security issues and breaches, and explains why you should use a Password Manager.
Tresor is a port of Vault by James Coglan to .net. When I first discovered Vault, it immediately checked the boxes I was looking for: It works everywhere as long as I have internet access, but it doesn't store any data that can be compromised. All I need to do is remember the service name and settings, and voila, there's my password without having to store it in yet another online database that can be compromised.
For more information about Vault, check the FAQ on https://getvau.lt/faq.html.
Please note that this port is not endorsed or in any way associated with James Coglan.
TresorLib has been published to Nuget, and the source code is available on GitHub. It is licensed under the GNU General Public License Version 3 (GPLv3).
Example usage:
var service = "twitter";
var phrase = "I'm the best 17-year old ever.";
var password = Tresor.GeneratePassword(service, phrase, TresorConfig.Default);
// password => c;q- q}+&,KTbPVn9]mh
For more usage information and documentation, check the Readme in the GitHub repository.
June 10th, 2017 in
Development | tags:
password,
security

It's been about 18 Months since I build a NAS for my own use and over time, my requirements have changed drastically. For one, I went with Windows instead of OpenBSD because I wanted to run some Windows-only software, and because NTFS works for backing up other NTFS Volumes, like my Home PCs. I've been using Backup4All Pro to backup the server to another external storage (a 3 TB Apple Time Capsule), including AES-256 Encryption.
There were 3 major issues with the hardware in my existing NAS:
- The case only fits 3 Hard Drives (2x 2.5" and 1x 3.5"), and I need some more space
- The CPU struggles with compression and encryption
- The RAM is not ECC
Number 1 would've been an easy fix, just get a different case, but - despite varying opinions - I want ECC RAM in my file server, and that required a new mainboard & CPU.
ECC RAM in the Intel world requires a workstation chipset (like the C232 or C236) and ECC supporting CPU, which would be a Pentium or Xeon. The Core i3/i5/i7 CPUs do not support ECC even though the lowly Pentium does, presumably to not cannibalize the Xeon E3 market. After all, the only real difference between a Xeon E3 and a Core i7 is ECC RAM support.
After looking around and pricing a CPU + Mainboard + ECC RAM Combo, I stumbled upon the Dell PowerEdge T30 tower server, which at least right now is on sale for $199 for the Pentium G4400/4GB ECC and $349 for the Xeon E3-1225 v5/8 GB non-ECC version, with coupon codes 199T30 and 349T30 (Update: These seem expired now). $199 definitely beats anything I can price together for a Case + Board + CPU + ECC RAM, so I ended up buying one as my new file server.
The Specs
- Intel Pentium G4400 CPU (2x 3.3 GHz Skylake, 3 MB Cache, 54W TDP, No Hyperthreading)
- 1x 4 GB DDR4-2133 ECC RAM - there are 4 slots, supporting a maximum of 64 GB. Dual-Channel, so with only 1 DIMM it's a bit of a waste.
- 1 TB 7200rpm SATA Hard Disk (mine is a Toshiba DT01ACA100, manufactured October 2016, 512 emulated sectors, 32 MB Cache)
- Intel C236 Chipset Main Board
- Front: 2x USB 3.0, 2x USB 2.0, Sound
- Back: 4x USB 3.0, Sound, HDMI, 2x DisplayPort, PS/2 Mouse and Keyboard, and Gigabit Intel I219-LM Ethernet
- Slots: 1x PCI Express 3.0 x16, 2x PCI Express 3.0 x4 Slots, and 1 old-school 32-Bit 33 MHz PCI slot
- Undocumented M.2 2280 SSD Slot - requires PCI Express M.2 SSD, can't use SATA/AHCI.
- 290 Watt Power Supply
- No Remote Management, at least on the Pentium (no DRAC either), although the Xeon CPU would support Intel AMT 11.0
- No Operating System
I ended up buying a few extra things:
- Kingston KTD-PE421E/4G - 4 GB DDR4-2133 ECC RAM, intended for the PowerEdge T30 (Kingston's compatibility list) - $45
- IO Crest 2 Port SATA III PCI-Express x1 Card (SY-PEX40039) with ASM1061 chipset - to add 2 more SATA Ports. No fancy RAID Controller needed here. - $15
- SATA Power Splitter Cable - power those two extra SATA drives since I don't have the official Dell cable. - $5
- Samsung PM951 128 GB NVMe SSD - after discovering the undocumented M.2 SSD Slot. - $75
So that's an extra $140 for a $199 server, but I couldn't have built anything better for $340.

Storage Options
The server supports up to 6 hard drives, with 4x 3.5" and 2x 2.5" slots. Instead of 2x 2.5" drives, a slim laptop optical drive can be installed. However, there are only 4 SATA ports on the mainboard (Intel RST, supports RAID), and by default only power cables for 4 drives as well (2 for the bottom, 2 for the top). That's why I ended up buying a cheap 2-Port SATA controller and a SATA power splitter cable.
If you want to run 6 drives, consider the official Dell cable:
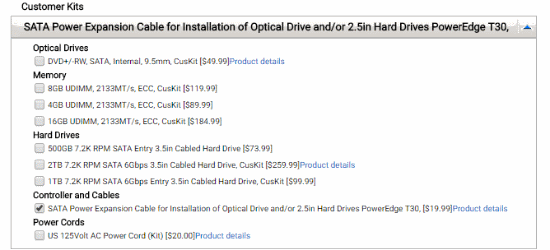
512-byte sectors
One interesting tidbit is that the hard drive is using 512e sectors, that means that even though internally the drive uses 4K Advanced Format, the system actually sees a drive with old-school 512 Byte Sectors. This can help with compatibility issues, because some systems (e.g., VMWare ESXi/vSphere) don't support 4K Sector drives.
Since Dell doesn't specify the type of drive you get, there might be other drives as well, but I think that 512e sectors makes sense for a server that's without an operating system.
Since I don't run VMWare and since my other data drives are 4K Sectors, the OS Drive being 512e doesn't matter to me.
The M.2 Slot
There is an undocumented M.2 Slot on the mainboard. Actually, there are two, one in the rear of the case that's not actually provisioned (no slot on the board, but the soldering points are there) and one M.2 Slot in the bottom right under the RAMs, that is actually provisioned and working - until BIOS 1.0.3 (and 1.0.5 as well).
I get 900 MB/s reading from the 128 GB Samsung PM951, and it's possible to boot off it. at least until BIOS 1.0.2, which is what I'm running. I reached out to Dell to ask them to reconsider disabling the slot - it's undocumented, but it works. I don't know if the comparatively low speed is because the PM951 is slow or if the M.2 Slot is only connected to 2 PCIe Lanes, but I'd take a 2-Lane M.2 slot over no slot.
Update July 2017: BIOS 1.0.5 fixed the Intel Management Engine remote exploit, which you absolutely must have if you have a Xeon. But that also means no M.2 Slot, and it's highly unlikely that Dell will enable it back.
Drive Setup and Backup Strategy
- 1 TB Toshiba DT01ACA100 - Intel RST - OS Drive, Windows Server 2012 R2 Standard
- 2x 1 TB 2.5" WD Red WD10JFCX - RAID 1 on Intel RST - Important Data like documents, photos and emails - stuff I can't get back
- 4 TB WD Red WD40EFRX - Intel RST - Big Stuff like Videos, Installers and just a giant grabbag of files that I can get back or afford to lose
- 3 TB WD Red WD30EFRX - ASM1061 - Backups from my local machines
- 128 GB Samsung PM961 - M.2 Slot - Not in use yet, didn't want to waste it on the OS, but keep if I need super-fast storage (e.g., upgrade to 10 GBit Network and use as iSCSI Target)
Backup strategy
I haven't set it all up yet, but the idea is to have a multi-stage backup. First off, local machines on my network just store files on the server or regularly backup onto the 3 TB drives using Windows Backup. For the data on the Server, I use Backup4All Pro to create an AES-encrypted backup to an external drive. For the longest time, this used to be an Apple Time Capsule, but that thing only supports SMB1, which is horribly broken and insecure, so that's no longer an option. Since I still have my old server (it's becoming a service box since I want to keep this file server here as clean as possible), I think I'm going to move the drive from the Time Capsule into it.
That gives me several levels of protection locally, but I'm also planning to archive to Amazon Glacier. Backup4All supports backing up to Amazon S3, and it's possible to have S3 archive to Glacier, which makes this a good option. If you set the "Transition to Glacier" value to 0, it immediately goes to Glacier and no S3 storage fees apply - only transfer fees.
Once the entire Backup system is up and running, I'll create a separate post.
Future Upgrade-ability
Now, there are some thing to be aware of. First off, the 290W power supply has exactly two power cables, which both go into the mainboard. From the mainboard, there are exactly 4 SATA Power Connectors (unless you order the SATA Power Extension for an extra $20), which is exactly what you need for the 4 SATA ports on the mainboard.
Extensibility is really limited: If you were thinking of adding a powerful GPU, you won't have the 6 pin connector to drive it. If you want to add more hard drives (the case holds 4x 3.5" and 2x 2.5" drives), you'll need either Dell's SATA Power Extension (which they don't seem to sell separately) or a third party one that hopefully doesn't catch fire.
The C236 chipset supports Kaby Lake, so it should be possible to e.g., upgrade to a Pentium G4600 and get HyperThreading, or to a Skylake-based or Kaby Lake-based Xeon E3, assuming Dell doesn't have any weird BIOS limits in place.
Memory-wise, there are 4 DIMM slots in 2 Channels, which currently mean up to 64 GB DDR4 RAM.
Verdict
It's an entry-level server. It was reasonably priced, has ECC RAM, is really quiet, and does what I need. I like it.
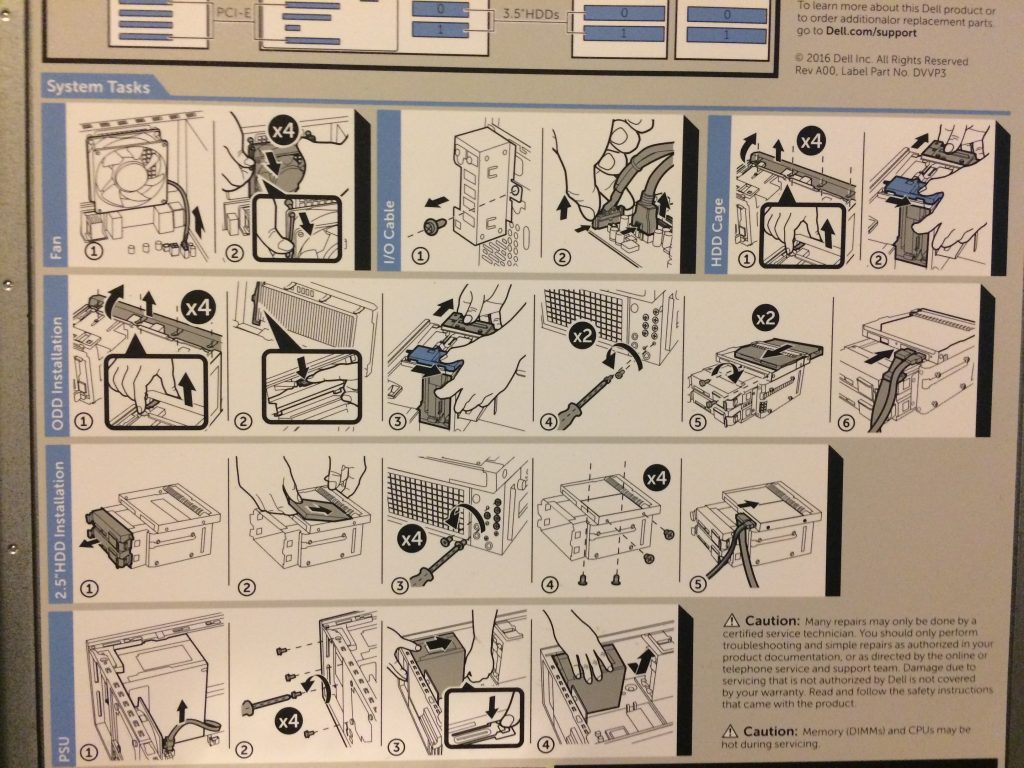
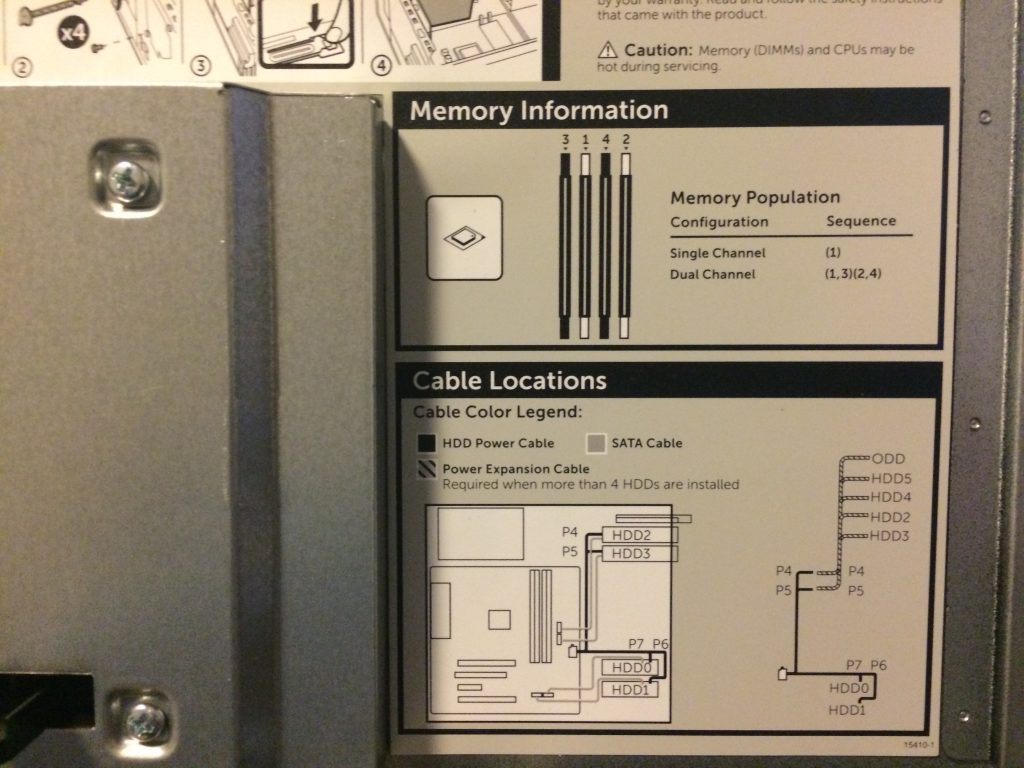
More Pictures (click to enlarge)


May 7th, 2017 in
Hardware
A couple of years ago, I created a simple .net Library to create Excel .xlsx sheets without the need to do any COM Interop or similar nonsense, so that it can be used on a web server.
I just pushed a major new version, Simplexcel 2.0.0 to NuGet. This is now targeting both .net Framework 4.5+ and .NET Standard 1.3+, which means it can now also be used in Cross-Platform applications, or ASP.net Core.
There are a few breaking changes, most notably the new Simplexcel.Color struct that is used instead of System.Drawing.Color and the change of CompressionLevel from an enum to a bool, but in general, this should be a very simple upgrade. Unless you still need to target .net Framework 4 instead of 4.5+, stay on Version 1.0.5 for that.
What is wrong with this picture?
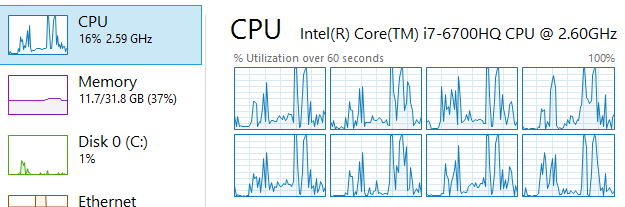
Answer: The white area in the top of the CPU and Memory graphs. These indicate that I spent money on something that I'm not using.
One of the complaints that are often brought forward how certain applications (especially browsers) are "memory hogs". As I'm writing this, Chrome uses 238.1 MB of RAM, and a separate Opera uses 129.8 MB. Oh my, remember when 4 MB were enough to run an entire operating system?
Now, here's the thing about RAM and CPU Cycles: I spend my (or someone elses) hard earned cash on it in order to speed up my computer use. That's literally why it exists - to make stuff go faster, always.
Having 32 GB of RAM cost about $200. In the above screenshot, about $135 of those hard earned dollars are just doing noting. It's like hiring (and paying) an employee full-time and only giving them 3 hours of work every day. That CPU? It's Quad-Core, Eight Thread, with 2.6 Billion Cycles per second - that's between 10 and 20 Billion total cycles each second. And yet, it's sitting at 16% in that screenshot. For a CPU that's priced at $378, that's $317 not being used.
There are priorities and trade-offs that everyone needs to make. In a Laptop, maybe you don't want the CPU to be constantly close to 100%, because it drains the battery and the whirring cooling fan is annoying. But maybe you bought such a high end laptop specifically because you want to use that much CPU power and RAM. I certainly did.
My primary application is Visual Studio, which has been making some really good strides in 2017 to be faster. Find all References is pretty fast, Go To Types is pretty fast. Just "Find in Files" could be faster because it still seems to hit the disk. The cost for that? Currently 520 MB RAM usage. I'll take that. In fact, if I could more speed at the expense of more RAM, I'd take that as well. In fact, I would love for Visual Studio to find a way to reduce the 45 Second build time - as you see in the graph, the CPU only briefly spikes. Why is it not constant 100% when I click the Build button? Is there a way to just have everything needed to compile constantly in RAM? (and yes, I know about RAM disks, and I do have a SSD that does 3 GB/s - but the point is for applications to be more greedy)
Two applications that I run that really make great use of my Computer are SQL Server and Hyper-V. SQL Server is currently sitting at 3.5 GB and will grow to whatever it needs. And Hyper-V will use whatever it needs as well. Both application also do respect my limits if I set them.
But they don't prematurely limit themselves. Some people are complaining about Spotify's memory usage. Is that too much for a media player? Depends. I'm not using Spotify, but I use iTunes. Sometimes I just want to play a specific song or Album, or just browse an Artist to find something I'm in the mood for. Have you ever had an application where you scroll a long list and halfway through it lags because it has to load more data? Or where you search/filter and it takes a bit to display the results? I find that infuriating. My music library is only about ~16000 tracks - can I please trade some RAM to make the times that I do interact with it as quick as possible? YMMV, but for me, spending 500 MB on a background app for it to be super-responsive every time I interact with it would be a great tradeoff. Maybe for you, it's different, but for me, iTunes does stay fast at the expense of my computer resources.
Yeah, some apps may take that too far, or do wrong behaviors like trashing your SSD. Some apps use too much RAM because they're coded inefficiently, or because there is an actual bug. It should always be a goal to reduce resource usage as much as possible.
But that should just be one of the goals. Another goal should be to maximize performance and productivity. And when your application sees a machine with 8, 16 or even 32 GB RAM, it should maybe ask itself if it should just use some of that for productivity reasons. I'd certainly be willing to trade some of that white space in my task manager for productivity. And when I do need it for Hyper-V or SQL Server, then other apps can start treating RAM like it's some sort of scarce resource. Or when I want to be in battery-saver mode, prioritizing 8 hours of slow work over 4 hours of fast work.
But right now, giving a couple of hundreds of megs to my Web Browsers and Productivity Apps is a great investment.
April 11th, 2017 in
Development